
What is Distributional? Explaining AI behavior through the language of statistical distributions
Statistical distributions give us a language to understand the uncertain world around us by assigning likelihoods to future events of interest through repeated observation. In some ways, distributions are the lingua franca of chance—mutually intelligible across all domains—from describing the rate of faulty computer chips in manufacturing to estimating the size and frequency of waves in oceanography. Nowhere, however, is the parlance of chance more apropos than the domain of AI systems.
In this piece I’ll discuss the opportunity for enterprises to increase the adoption of production AI systems—particularly GenAI systems—by gaining confidence that these systems will behave as desired once deployed. The key to this is evolving the notion of application testing so it is capable of communicating with AI in its native language of probability by way of statistical tests. By doing so, enterprises can deploy and maintain AI systems that continually pass these tests, signifying they are systems that have the highest tendency towards consistent desired behavior.
AI is distributional
Abstractly, GenAI systems are statistical distributions over natural language such that the goal is to predict the next token (letter, word, sentence, etc.) given a prompt and training corpus (which can be as large as the internet itself). From this premise, we get powerful applications like chatbots, LLM summarization, and AI agents. In building these systems we want to evaluate their distributions over performance metrics to find their propensity to correctly predict the next token or perform a specific task. Beyond that, we are interested in distributions which describe second-order properties (or metrics) of the system’s behavior itself, such as the likelihood that an LLM summarization system will deliver toxic, incoherent, or unreasonably long outputs. Because the outputs of AI systems can be represented by distributions over many metrics, their behavior can be described as “distributional.”
When it comes to developing and productionalizing these distributional AI systems, they require different considerations than those of traditional software applications. For one, traditional software applications exhibit consistent and repeatable workflows without deviation, and therefore one can expect the same behavior from the same input. Ergo, my word processor application returns the character I desire to type with each keystroke, without fail.
On the other hand, modern AI applications (both models and components) offer changing behavior over time for the same prompt or stimulus. Consider an LLM summarization application, for instance one used to summarize medical journals as part of an application sold to health practitioners. By its nature, this system may produce varying synopses of the same documents of interest, a property known as non-determinism. The model itself may also change over time, a quality known as non-stationarity. In the worst case scenario the outputs are inconsistent, inaccurate, too verbose, or even contain undesired words, thereby detracting from business value and causing operational risk to both vendor and consumer. In the best case scenario, all variations of summaries produced by the LLM are equally acceptable, accurate, and operable by the end user. This type of consistency is the desirable outcome for the vendor looking to increase revenue by providing such a beneficial AI application.
The AI Confidence Gap
Therefore, for the enterprise, the outcomes or behaviors of distributional AI systems must align with business goals, providing the highest chance of desired behavior and lowest risk of undesired behavior. Today, there are many groups of tools on the market to help enterprises develop and deploy such distributional systems—mainly those focused on evaluation when building an AI application, and those focused on monitoring once that application is in production. Where these tools fall short is in providing value between development and production, a phenomenon known as the AI Confidence Gap. That is, AI product teams (and the AI governance and compliance teams that oversee them), lack the confidence that the AI application created during development will behave as intended the minute real users utilize the deployed application at scale.
This disconnect is so severe that it prevents AI production teams from deploying AI applications due to fear of operational risks. For this reason it is known market-wide that nearly 1 in 3 GenAI projects will be abandoned after proof of concept by the end of 2025. Whereas in traditional software, the confidence gap between development and production is closed by rigorous testing, given AI systems are governed by the laws of probability, a new concept of AI specific testing is required to fill the void.
What is Distributional?
Enter Distributional, the platform and company that bear the name of AI’s intrinsic essence, and introduced the concept of distributional testing for AI applications. The key insight is that AI, by its nature, is a mixture of statistical distributions that can be queried to discover their central tendencies (and also their rare events). Hence, Distributional acts as an interpreter for AI, allowing product teams to statistically define consistency of AI application behavior, and then continuously confirm or identify changes in this behavior over time. Armed with statistical visibility into AI application behavior, AI product teams can confidently bridge the AI Confidence Gap.
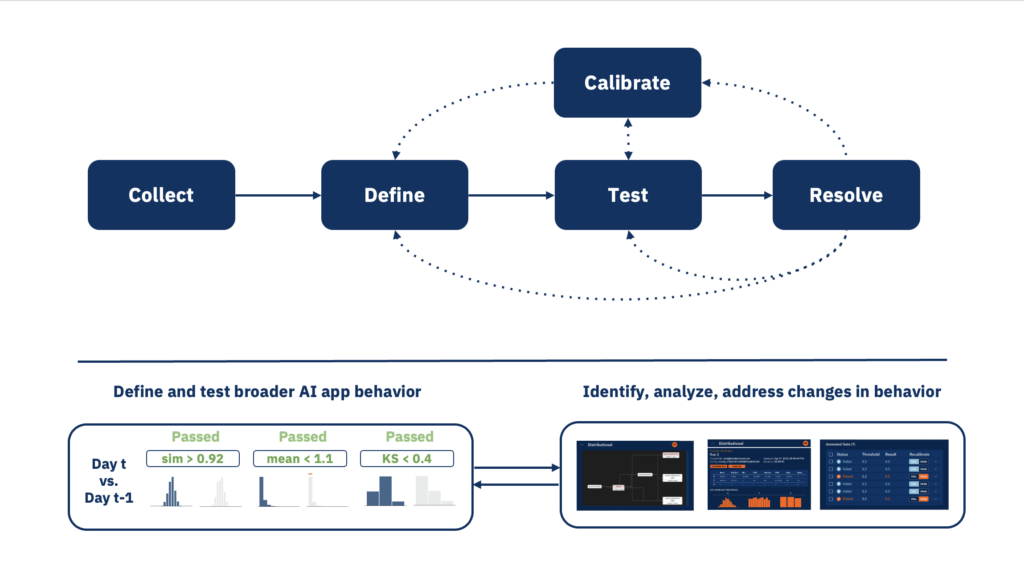
How Distributional works
Functionally, Distributional provides an innovative approach that enables enterprise AI teams to understand, manage, and test the reliability of their AI systems so they can gain confidence in their behavior. Here is a simplified version of how this automated workflow works:
- Integrate: Point Distributional at your data storage for an AI application, any input, output, or intermediate data that the application produces
- Run: Collect data on regular basis from this data storage using your current orchestration or CI tooling
- Derive: Use Distributional’s eval library to derive testable behavioral properties from your data
- Test: Apply statistical test templates to these properties that assess consistency in AI application behavior across distributions of these testable properties run over run
- Triage: Analyze test results in the Distributional dashboard to decide whether the tests need to be calibrated to fit the app or app debugged to fit the tests
- Resolve: Recalibrate tests within Distributional or debug the application off platform with insights from Distributional
This allows for apples to apples comparisons of the same production application over time or between new applications in development and those currently in production. As a result, teams feel confident in steady state AI app behavior and can quickly get back to steady state as their apps evolve.
The Distributional Fingerprint
In the next piece in this series I will go deeper into this workflow. Although Distributional can be applied to any AI/ML application I will make this concrete by showing you how it works on a simple Q&A RAG application. In doing so we will see Distributional’s main features, namely the ability to produce an AI application’s Distributional Fingerprint (i.e. its unique baseline mixture of characteristic distributions), automate and apply statistical tests, detect and understand behavioral change to the Distributional Fingerprint, and enable AI governance through a standardized, repeatable, consistent, and visible testing process.
Interested in trying Distributional? Here are some next steps and ways to learn more: